How to Read Paintings: Semantic Art
Understanding with Multi-Modal Retrieval
Aston University
Abstract
Automatic art analysis has been mostly focused on classifying artworks into different artistic styles. However, understanding an artistic representation involves more complex processes, such as identifying the elements in the scene or recognizing author influences. We present SemArt, a multi-modal dataset for semantic art understanding. SemArt is a collection of fine-art painting images in which each image is associated to a number of attributes and a textual artistic comment, such as those that appear in art catalogues or museum collections. To evaluate semantic art understanding, we envisage the Text2Art challenge, a multi-modal retrieval task where relevant paintings are retrieved according to an artistic text, and vice versa. We also propose several models for encoding visual and textual artistic representations into a common semantic space. Our best approach is able to find the correct image within the top 10 ranked images in the 45.5% of the test samples. Moreover, our models show remarkable levels of art understanding when compared against human evaluation.

SemArt Dataset
SemArt dataset is a corpus with 21,384 samples that provides artistic comments along with fine-art paintings and their attributes for studying semantic art understanding.



Results
Text2Art Challenge
Text2Art challenge, based on text-image retrieval, is used to evaluate the performance of semantic art understanding, whereby given an artistic text, a relevant image is found, and vice versa.
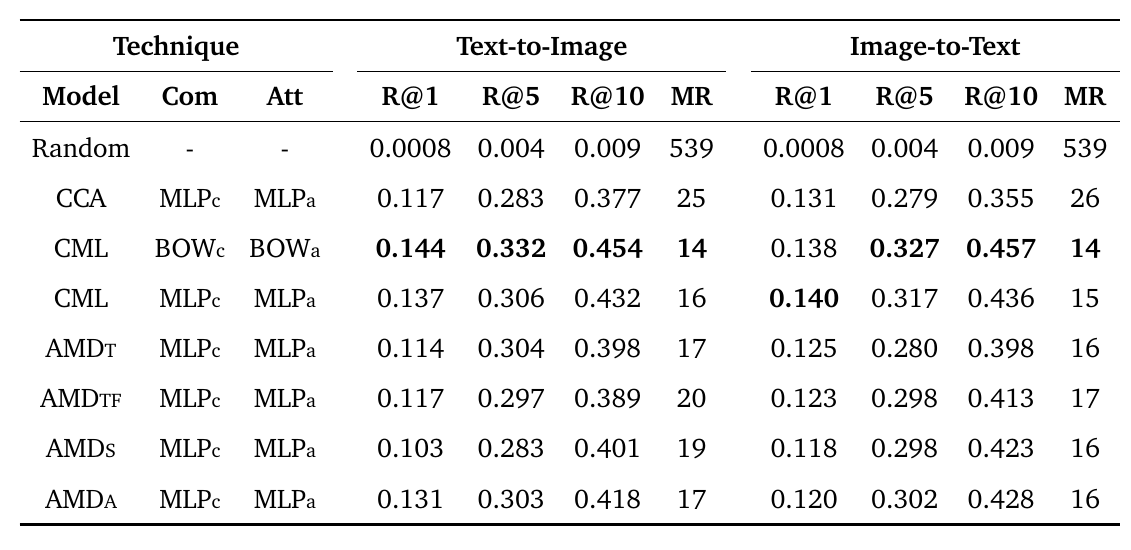
Human Evaluation
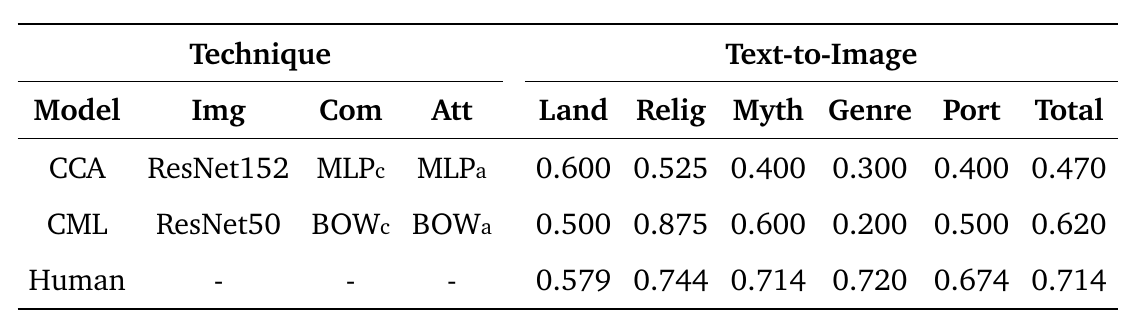
For a given artistic comment and attributes, standard human evaluators (i.e. not art experts) were asked to choose the most appropriate painting from a pool of ten painting images. We evaluate the task in two different levels: easy and difficult.
- In the easy level, images shown for a given text are chosen randomly from all the painting images in test set.
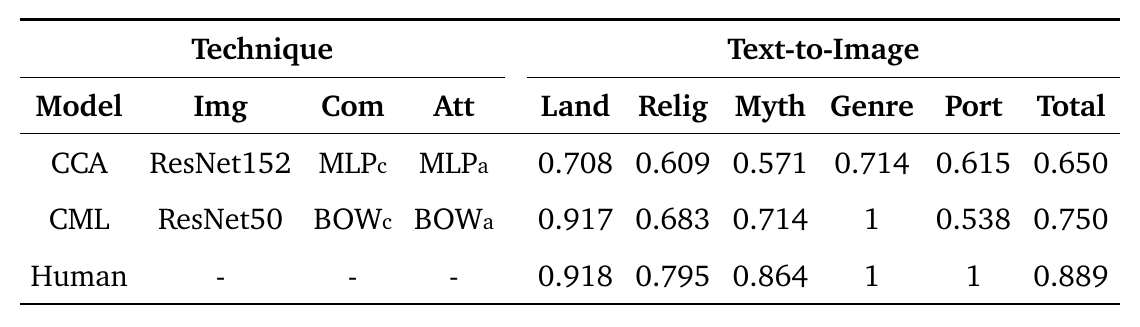
- In the difficult level, ithe ten images shown for each comment share the same metadata field type.
Examples




Code & Models
Download
Coming soon
Citation
@InProceedings{Garcia2018How,
author = {Noa Garcia and George Vogiatzis},
title = {How to Read Paintings: Semantic Art Understanding with Multi-Modal Retrieval},
booktitle = {Proceedings of the European Conference in Computer Vision Workshops},
year = {2018},
}